The amount of spatial data about earth systems is growing, opening new doors to evaluate and quantify complex processes involving both humans and nature. Nature in cities is, for example, a key to economic performance and liveability. While the new technologies provide many new opportunities to understand and plan socio-ecological systems, it is unclear how these new technologies can successfully be implemented to shape landscapes that provide societally valued and needed qualities.
Ecosystem services (ES) provided by nature in cities are receiving increasing attention by planners and authorities. From health benefits to energy bill reductions, they contribute directly to the well-being of citizens and provide habitat for many species supporting biodiversity.
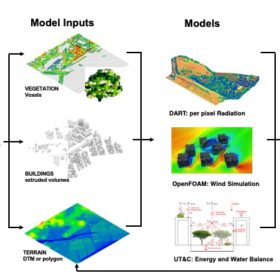
Thanks to the development of Earth Observation technologies, an increasing amount of spatial data about the planet’s physical, chemical, and biological systems is becoming available on platforms like the USGS Earth Explorer, the NASA Earth Observation, or the European spatial agency’s Sentinel, among others. From high resolution satellite images to twitter data, big data can be used to map the demand for and supply of ecosystem services. The same datasets, particularly LIDAR (light detection and ranging) can also be used by landscape architects to design changes in the landscapes or by hydrologists to understand hydrological processes. Such datasets thus provide a means for interdisciplinary workflows to shape landscapes that provide societally valued and needed qualities.
Within the Singapore Natural Capital Project that aims to assess ecosystem services in the megacity of Singapore, we carried out a pre-study to analyse the state and trends of ES using big data from satellites and global databases. General results are promising and the interdisciplinary potential of the data has been proven by assessing the cooling effect of various landscape designs.
The generation and use of these vast datasets of our environment also come along with important challenges. On one hand, many datasets are collected without a clear research aim (e.g., geotagged Twitter was never produced to provide answers with respect to the spatial distribution of people neither the drivers of such processes). The data is reflective of the technique used to generate it and holds certain characteristics. Details about the production of the dataset and the validation of the data are thus crucial to avoid mistakes in the results and interpretations. On the other hand, some datasets are not accessible to the general public or data is filtered out to provide only a selected area or a defined resolution to the user. Attention needs to be paid to secure the access to data and enhance the ability of the public to understand not only what is presented to them, but also what are the assumptions of the new technologies to generate information and choice. Another important challenge is the large computer power needed to process big data and the requirement of specific software, in addition to man power and technical skills.
While the opportunities of big data to support humans to intentionally transform landscapes are thus tremendous, the question remains on how this new data will change the way we understand and design landscapes and how we will interact with them. In particular, we will need to better understand how the use of such data can create a knowledge-driven rather than a data-driven design and planning process.
Dr. Marcelo Galleguillos is research associate at IRL-PLUS; Prof. Dr. Adrienne Grêt-Regamey is professor at IRL-PLUS.
Lesen Sie auch
Eine neue Schweizer Landschaftstypologie mit Deep Learning
» Newsletter-Artikel